Rapport final
Categories:
Plateforme CEDILLE - Rapport LOG791
Introduction
Dans le cadre du cours LOG-791 et de notre engagement au sein du club Cedille de l’École de Technologie Supérieure (ÉTS), nous avons entrepris le projet de faire la conception et la mise en place de la Plateforme CEDILLE. Ce rapport vise à présenter de manière exhaustive les différentes étapes de notre initiative, depuis sa genèse jusqu’à sa concrétisation actuelle.
Le projet de la Plateforme CEDILLE avait pour objectif principal de transformer l’infrastructure existante du club. Nous avons choisi d’implémenter un cluster Kubernetes sur des serveurs physiques, en exploitant les capacités de Talos OS et la solution Omni de Sidero Labs. Cette démarche se voulait doublement bénéfique : réduire les coûts associés à l’hébergement tout en offrant une opportunité concrète d’apprentissage et de développement des compétences en DevOps, Kubernetes et gestion de serveurs.
Aujourd’hui, nous sommes fiers de constater que la majorité de l’infrastructure et des services systèmes sont opérationnels. Cependant, il convient de souligner que certaines phases de la migration des services hébergés restent à compléter. Ce rapport se propose donc de dresser un bilan de notre parcours, soulignant aussi bien les réussites que les obstacles rencontrés et les enseignements tirés de cette expérience.
Dans les sections suivantes, nous détaillerons la méthodologie adoptée pour la réalisation de ce projet, ainsi que les étapes de développement et de mise en œuvre. Nous mettrons en lumière les défis techniques et organisationnels rencontrés, ainsi que les solutions déployées pour les surmonter. Un éclairage sera également porté sur les alternatives technologiques envisagées, afin d’offrir une vision complète de nos choix et de notre processus de décision.
Nous analyserons ensuite les résultats obtenus, évaluant le succès du projet au regard des objectifs initiaux et des livrables. Un focus particulier sera accordé aux apprentissages et compétences développés tout au long du projet, témoignant de l’impact formateur de ce projet sur l’ensemble des membres de l’équipe. Enfin, la conclusion résumera nos principales réalisations et proposera des recommandations pour les futurs projets de nature similaire.
Par le biais de ce rapport, nous aspirons à vous fournir une vue d’ensemble exhaustive de notre parcours, mettant en évidence nos réalisations ainsi que les leçons clés tirées au cours de cette expérience.
Méthodologie
Pour mener à bien le projet Plateforme CEDILLE, notre équipe d’étudiants a adopté une approche pratique et flexible, combinant des outils de collaboration modernes et des méthodes de travail adaptées à notre contexte étudiant.
Planification initiale et vision du projet
Au début du projet, nous avons commencé par une phase de planification détaillée. Pour cela, on a utilisé un grand tableau pour visualiser l’ensemble de notre stack technologique et comprendre comment les différents éléments interagissaient entre eux. Cette étape a été cruciale pour nous aider à rédiger notre document de vision. Ce document a servi de feuille de route pour tout le projet, en définissant clairement nos objectifs et notre approche.
Organisation du travail et backlog
Une fois notre vision établie, nous avons dressé une liste exhaustive de toutes les tâches à réaliser dans notre backlog sur GitHub. Cela nous a permis d’évaluer l’ampleur du projet et de diviser le travail en trois grandes itérations d’un mois chacune. Cette approche itérative nous a aidés à rester concentrés et à mesurer notre progression de façon régulière.
Retrospectives et ajustements
Après chaque itération, on prenait le temps de faire une rétrospective. Ces moments étaient essentiels pour réfléchir à ce qui s’était bien passé et à ce qu’on pouvait améliorer pour la suite. Grâce à ces rétrospectives, on a pu ajuster notre planification et notre approche pour les itérations suivantes, en tirant des leçons de nos expériences précédentes.
Documentation et suivi sur le wiki
Toute notre progression a été soigneusement documentée sur notre wiki. Pour chaque tâche ou problème rencontré, on créait une entrée sur le wiki avec des liens directs vers les issues correspondantes sur GitHub. Cela a permis à toute l’équipe de suivre facilement l’avancement du projet et de retrouver rapidement les informations pertinentes liées à chaque tâche.
Réunions et communication
La communication constante et efficace a été un pilier de notre projet. Nous avons organisé des séances de travail en présentiel chaque dimanche à l’école pour une collaboration et des discussions techniques approfondies. En complément, des réunions hebdomadaires sur le modèle Scrum étaient tenues tous les lundis, permettant à l’équipe de discuter des avancées, de planifier les prochaines étapes et de résoudre les obstacles rencontrés.
Adoption des principes Agile et DevOps
Notre processus de collaboration a été fortement influencé par les principes Agile et DevOps. Nous avons adopté une approche itérative pour le développement, permettant une adaptation et une réactivité rapides aux changements. Le déploiement continu et les mises à jour de notre architecture ont été gérés via l’Infrastructure as Code (IaC), en utilisant des pipelines CI/CD pour automatiser et rationaliser ces processus. De plus, l’utilisation de templates pour les issues et pull requests sur GitHub a renforcé notre efficacité et a maintenu une norme de clarté et de cohérence dans notre communication et nos pratiques de développement.
Architecture technique
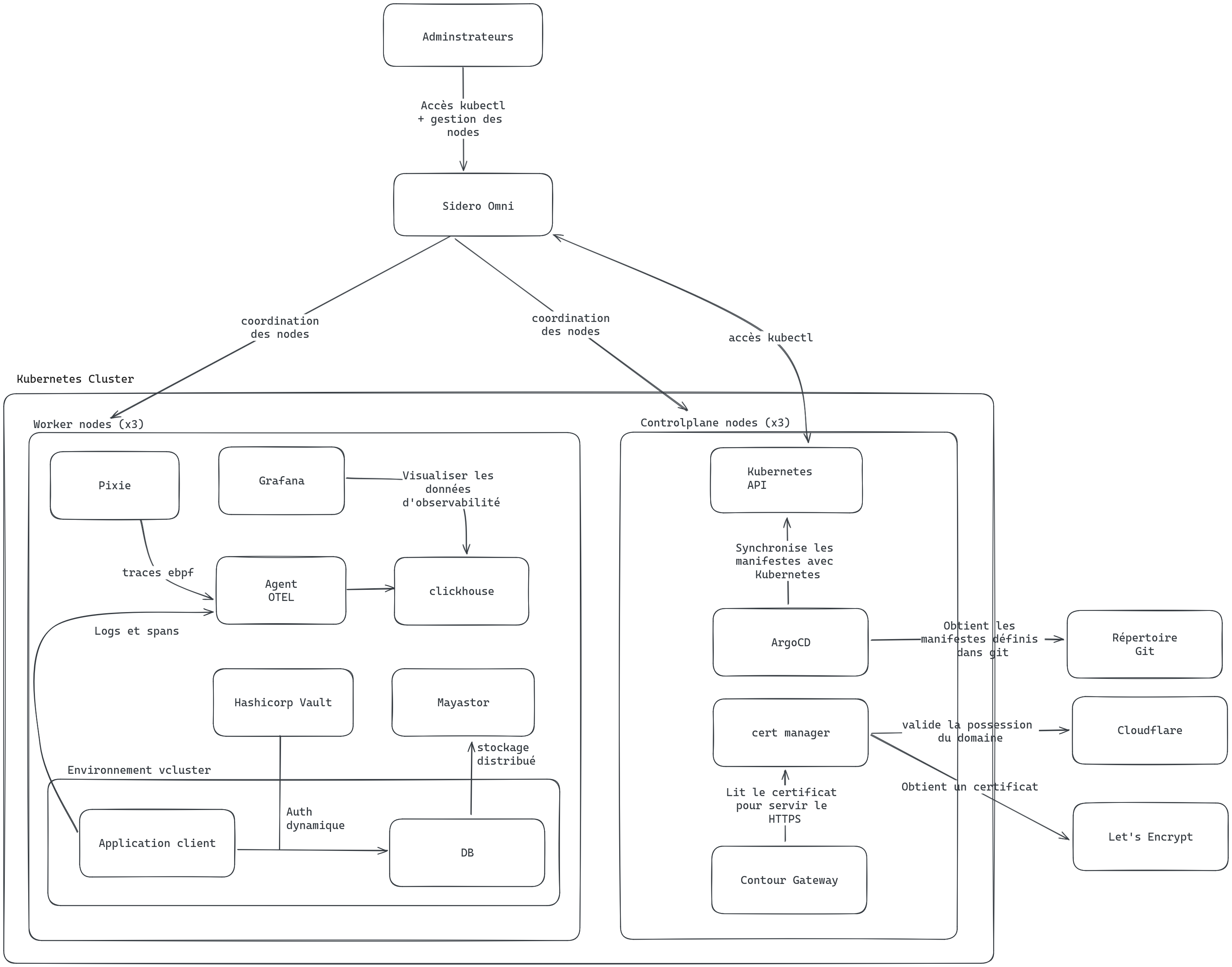
Kubernetes et Sidero Omni
Pour la gestion des applications déployées, nous avons choisi d’utiliser la technologie des conteneurs. Cela permet une meilleure isolation entre les différentes applications et une gestion plus facile des dépendances grâce aux Dockerfiles. Pour gérer les déploiements de conteneurs sur nos systèmes, nous avons choisi d’utiliser Kubernetes puisque c’est le standard en entreprise et que ses capacités de coordination sont extrêmement puissantes. Kubernetes permet 2 types de nodes: controlplane et worker. Dans notre cas, nous avons déployé 3 controlplanes et 3 workers. Les 3 controlplanes permettent au cluster Kubernetes lui-même d’avoir une haute disponibilité (si un des nodes est éteint ou mis à jour, il n’y a pas d’impact sur les capacités du cluster). Les 3 workers permettent aux applications ainsi qu’au stockage d’avoir de la haute disponibilité.
Kubernetes est un système, mais ce n’est pas proprement un système d’exploitation. Ici, nous avons choisi Talos OS: c’est un système d’exploitation Linux entièrement construit autour de Kubernetes. La plupart des processus que l’on trouve dans un système Linux standard sont d’ailleurs manquant afin de réduire la surface d’attaque. De même, une partie importante du système de fichier est en lecture seule.
L’autre avantage de ce système d’exploitation est qu’il peut être entièrement contrôlé par un API, permettant donc de meilleures automatisations. La compagnie qui a développé cet OS a d’ailleurs aussi développé un service SaaS qui se connecte à cet API et automatiser une partie importante de la gestion du cluster: Sidero Omni. Puisque que Sidero est un commanditaire du club étudiant, nous avons droit à une license pour utiliser ce logiciel habituellement payant. Cela nous permet de gérer facilement les différents serveurs à distance via une interface web. Le contrôle via l’API Kubernetes passe aussi par cette solution SaaS, permettant donc un contrôle des accès plus strict avec OAuth.
Gestion GitOps
Pour la gestion des déploiements et des configurations, nous avons choisi une approche pleinement GitOps. Cette approche permet de réduire les étapes impératives et difficiles à reproduire pour avoir des environnements faciles à reproduire. De plus, la traçabilité de git permet d’avoir des flux de contrôle de changements plus avancés et d’identifier la source du problème plus rapidement.
Pour atteindre cet objectif de GitOps, nous avons donc utilisé deux outils : ArgoCD et Terraform. ArgCD est un outil spécifique à Kubernetes, qui est déployé sur le cluster. Celui-ci surveille tous les manifestes Kubernetes sur le répertoire Git et fait les modifications nécessaires pour que le cluster soit configuré accordément à ces manifestes. Cela peut être des configurations comme des déploiements applicatifs. Le second outil, Terraform, est surtout utilisé pour configurer les dépendances autours de Kubernetes. Cet outil permet de définir des configurations de services cloud et de lier des variables entre elles entre plusieurs services, offrant une composition de ressources cloud très puissante. Pour le moment, la création de répertoire git ainsi que la configuration du service de gestion de clées KMS de Google Cloud sont les deux principaux services configurés avec Terraform.
Stockage distribué
Afin d’offrir un service de qualité, il est important que les services restent toujours disponibles même en cas de pannes ou mises à jour de système. Kubernetes offre une façon de distribuer des ressources applicatives pour atteindre de la haute disponibilité. Toutefois, lorsque des données persistantes sont impliquées, cela est un peu plus complexe. En effet, Kubernetes laisse le soin aux administrateurs le soin de définir le stockage, ne fournissant qu’une abstraction. Cela permet une architecture très flexible (compatible autant avec des environnements physiques que cloud), mais implique plus de travail pour le configurer. Une solution simple consiste à utiliser le stockage local d’un noeud pour enregistrer les données. Toutefois, avec cette solution, si le noeud tombe en panne, les données deviennent indisponible et on perd la disponibilité de l’application. Pour éviter cette situation, il faut repartir les données sur différents serveurs de façon à ce qu’il y ait toujours un minimum de 2 copies de chaque donnée sur 2 différents serveurs.
Plusieurs technologies permettent de faire cela, ici, nous avons choisi Mayastor. C’est un engin de stockage basé sur la spécification NVMe-oF, un protocole de disque plus récente que SCSI et qui permet de mieux bénéficier des capacités de parallélisation des SSD. Mayastor est aussi pleinement conçu pour et intégré avec Kubernetes, réduisant les risques de problèmes de compatibilité qui sont parfois présents avec des engins d’abord conçus pour des systèmes non-Kubernetes.
Pour les applications, ils n’utilisent pas directement Mayastor, mais plutôt les abstractions Kubernetes: StorageClass, PersistentVolumeClaim et PersistentVolume. Cela nous permettrait de changer l’engin de stockage dans le futur si nécessaire.
Gestion des secrets
La gestion des secrets est toujours un aspect complexe et où une mauvaise configuration peut avoir des conséquences désastreuses. C’est d’ailleurs souvent à travers la gestion des secrets que l’on voit des pirates informatiques infiltrer des systèmes. Ici, nous avons choisi d’utiliser Hashicorp Vault, standard dans l’industrie pour la gestion de secrets à grande échelle. Pour configurer celui-ci, nous avons déployé un outil développé par la communauté RedHat: Vault Config Operator. Cet outil ajoute des définitions de manifestes Kubernetes (CRD), nous permettant de créer des politiques d’accès, des configurations de rotation de clées ainsi que de définir de nouveaux secrets aléatoires à travers des manifestes Kubernetes qui sont ensuite déployés par ArgoCD. Cette approche nous permet de conserver une approche GitOps sans avoir à exposer les secrets dans les fichiers sur Git.
Observabilité
L’observabilité est une pierre angulaire de toute approche DevOps, permettant à la fois au développeur et aux administrateurs d’identifier rapidement la source d’un problème. Dans un système distribué comme celui que nous avons conçu, les traces sont particulièrements importantes, puisque c’est ce qui nous permet de suivre le chemin d’une requête à travers les multiples systèmes.
Afin de collecter ces traces, nous avons mis à profit un outil appelé Pixi. Cet outil utilise une innovation relativement récente du noyau Linux: eBPF (extended Berkeley Packet Filter). Ceci permet à des applications de rouler certaines opérations dans le contexte privilégié du noyau Linux de façon sécuritaire. Ceci permet à Pixi d’analyse les communications entre les processus et le réseau et de recréer automatiquement des traces, sans avoir à configurer chaque composante pour qu’elle ajoute son contexte à la trace. Par la suite, ces traces sont exportées vers un agent OpenTelemetry. OpenTelemetry est un standard pour tout ce qui est observabilité et permet de faciliter le transfert de traces, métriques et logs entre plusieurs systèmes. Les agents OpenTelemetry agissent comme échangeurs, permettant de recevoir et retransemettre des traces, métriques et logs. Ici, nous redirigeons ces informations vers la base de données de haute performance Clickhouse. Enfin, nous utilisons Grafana pour se connecter à cette base de données et afficher toutes ces traces, métriques et logs.
Autres solutions envisagées
Pendant la phase d’analyse, on a identifié que certains choix techniques pouvaient être réalisés de plusieurs façons. Ainsi, dans le document de vision, on a identifié ces options et on s’est prononcé sur un choix initial (Tableau 4.4.2). Cependant, la phase d’implémentation nous a permis d’avoir une meilleure perspective sur certains choix et la possibilité de les changer. Ainsi, on présente ces choix ici :
Choix de l’engin de stockage
Selon le CAR8, on a planifié d’utiliser Rook-Ceph comme engin de stockage pour Kubernetes. À titre de rappel, l’engin est responsable de fournir un service qui répond aux requêtes CSI dans Kubernetes afin d’allouer des espaces dédiés au pods, d’assurer que ces espaces sont accessibles dans tout le cluster et que les données soient durables et intègres.
Rook-Ceph est une extension de Ceph, qui est un système de stockage distribué qui prédate Kubernetes. En principe, ce dernier répond à tous nos besoins en termes d’engin. Cependant, en pratique, on a remarqué que le système était très instable à notre échelle (3 serveurs).
Après plusieurs essais, on a choisi de remplacer Rook-Ceph par Mayastor, qui est un système conçu dès le début pour Kubernetes. Au final, le déploiement était plus simple et le système est très stable.
Choix de l’engin de gestion des secrets
Étant donné le fait que notre répertoire de code est public et qu’on utilise l’approche GitOps, il est impératif qu’aucun secret ne soit divulgué dans le répertoire de code source. Ainsi, il nous faut une solution logicielle qui fait abstraction des secrets afin de les gérer de manière sécuritaire. Donc, les deux choix principaux pour le faire sont Hashicorp Vault vs Bitnami Sealed Secrets.
Bitnami Sealed Secrets: Les secrets sont quand même présents dans git, mais ils sont cryptés. HashiCorp Vault: Les secrets ne sont pas dans Git, mais leurs configurations et des références le sont. Il offre aussi plusieurs modes de cryptage avancés, la génération dynamique, la rotation automatique et plusieurs autres fonctionnalités avancées.
Ainsi, on a déterminé que Vault serait une meilleure solution pour ce projet puisqu’on le juge plus sécuritaire (puisqu’aucun secret n’est divulgué publiquement comme dans le cas de sealed-secrets) et qu’on aurait besoin des fonctions plus avancées qu’il nous offre.
Choix de la plateforme d’observabilité
Selon le CAR13, on a choisi d’utiliser les technologies ouvertes Pixie, OpenTelemetry et Clickhouse dans une configuration construite sur mesure pour les fins d’observabilité. L’autre choix était de prendre une solution commerciale / tout-en-une, tel que Elastic ou Groundcover.
Ce qui influence notre choix pour cet aspect est qu’une considération importante pour Cédille est de promouvoir l’utilisation de logiciels libres. Ainsi, utiliser des solutions commerciales est à l’encontre de cet objectif, et on essaye d’éviter ce genre de choix quand c’est possible. De plus, on a jugé que la construction d’une solution sur-mesure en combinant ces technologies (Pixie, OpenTelemetry et Clickhouse) aurait une plus grande valeur en tant qu’apprentissage et donnerait un résultat qui répondrait mieux à nos besoins.
Choix d’utilisation d’un Hypervisor
Avant la phase d’analyse et rédaction du document de vision, on a entrepris une phase d’installation et configuration du matériel physique. Dans cette phase, on avait essayé en premier d’utiliser l’hyperviseur XCP-NG comme système d’exploitation principal, le plan étant de configurer nos clusters Kubernetes avec des machines virtuelles.
Afin de respecter notre objectif d’utiliser des configurations déclaratives le plus possible, on devait faire une gestion exhaustive de l’hyperviseur, de son réseau et de son stockage avec Terraform. Ainsi, on n’était pas prêt à accepter le niveau de complexité qui aurait été ajouté par cette méthode, donc on a choisi d’installer Talos Linux directement sur les machines sans Hypervisor.
Le résultat final est que la majorité des configurations et installations sont faites nativement dans le cluster Kubernetes, ce qui offre un haut niveau de cohérence dans le code du projet.
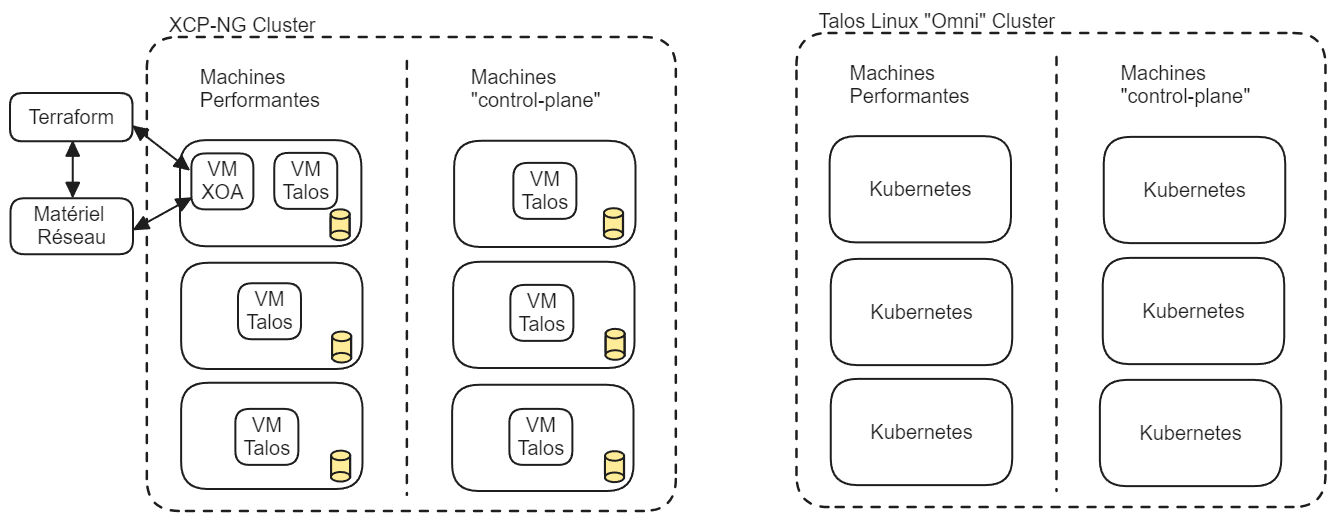 Figure: Comparaison des moyens de déploiement
Figure: Comparaison des moyens de déploiement
Défis et Solutions
| Défi | Problème | Solution |
|---|---|---|
| Installation de Kubernetes/Talos | Cryptage des disques non fonctionnel | Désactivation du cryptage avant installation |
| Installation brisée si clé USB retirée | Réinstallation avec identifiants de disque durables | |
| Configuration d’ISO dans PVC pour KubeVirt | Besoin de simplifier la gestion des PVCs | Utilisation du CDI de KubeVirt |
| Installation de Rook-Ceph | Cluster Ceph inutilisable, échec des OSD | Effacement manuel des disques et redémarrage de l’opérateur |
| Stabilité de Rook/Ceph | Instabilité après redémarrage d’un node | Remplacement par Mayastor |
| Configuration d’un service mesh | Problèmes avec Linkerd et mTLS | Choix de Kuma pour mTLS et support de Gateway API |
| Installation du service External-DNS | Service non fonctionnel, cause inconnue | Enquête en cours, exploration de solutions alternatives |
| Configuration SSO pour ArgoCD | Gestion non sécurisée des secrets | Utilisation de Vault pour la gestion sécurisée des secrets |
| Bootstrapping de Hashicorp Vault | Processus manuel complexe | Automatisation partielle via Terraform et scripts |
| Déploiement de Calidum-rotae | Acheminement partiel des requêtes | Configuration directe d’une webhook Discord |
| Enregistrement de VCluster dans ArgoCD | Difficulté d’enregistrement sécurisé | Utilisation de Crossplane pour enregistrement déclaratif |
Résultats
Notre projet a connu une progression significative, marquée par une série de tâches réalisées avec succès, chacune contribuant de manière essentielle à l’avancement global. Voici un résumé des tâches accomplies, présentées dans l’ordre chronologique de leur réalisation ainsi que par livrable :
Livrable 1: Phase initiale de préparation et d’entrevues. Déploiement et configuration initiale
- Préparation de questionnaires spécifiques à chaque client et conduite d’entrevues avec divers clubs et services de l’ÉTS, notamment AlgoETS, Raconteurs d’Angles, Saveurs de Génie, et les services TI. Ces entrevues ont permis de définir les métriques de succès du projet.
- Mise en place du cluster physique avec Talos/Omni et configuration de base de Rook/Ceph. Evaluation de la stack de networking pour Kubernetes.
- Création d’un wiki pour centraliser la documentation et rédaction du document de vision initial.
- Migration physique des serveurs vers la salle de serveurs et configuration de KubeVirt.
Livrable 2: Développement et configuration avancée
- Déploiement d’un cluster sandbox avec Vcluster, installation et configuration de l’external-dns, Hashicorp Vault, et Crossplane sur le cluster.
- Mise en place de la structure Kustomize, configuration d’ArgoCD, Contour (reverse-proxy/ingress), et déploiement de Kuma + Merbridge (service-mesh).
- Configuration et déploiement de Grafana, Gateway API, et Mayastor.
- Documentation approfondie de KubeVirt, Kuma, Merbridge, et Contour.
Livrable 3: Finalisation et optimisation
- Déploiement de cert-manager, documentation de Mayastor et de la configuration d’environnement locale avec Omni.
- Configuration d’OTEL, suivi de Clickhouse avec Open Telemetry, et déploiement d’exemples d’applications comme Grav et Calidum-Rotae.
- Mise à jour de l’architecture dans le README.md, suppression de composants obsolètes (base de données PostgreSQL, numéro de téléphone dans le protobuf), et instrumentation de l’application avec OTEL.
Tâches en cours et non réalisées
Bien que de nombreuses tâches aient été menées à bien, certaines sont encore en cours, notamment le déploiement de cert-manager et la documentation de Vault. Par ailleurs, l’intégration des vclusters avec ArgoCD est en cours de réalisation.
En termes de tâches non réalisées, nous avons décidé de ne pas poursuivre l’installation/configuration de k8s-sigs/external-dns dans le cluster, en raison de contraintes spécifiques au projet.
Résultat final
Notre projet a conduit à l’établissement d’une plateforme de déploiement capable de gérer une variété de services. Cette plateforme marque un progrès dans notre façon de déployer, gérer et surveiller les services informatiques, offrant une solution qui répond aux besoins variés de chaque club.
Pour des applications web, des bases de données ou des services de backend, elle fournit la flexibilité et les capacités nécessaires pour une gestion efficace et sécurisée des déploiements. Avec des outils tels qu’ArgoCD et Kustomize, le processus de déploiement est automatisé, facilitant des mises à jour et une maintenance continues.
Dans le domaine de l’observabilité et du monitoring, la plateforme intègre OpenTelemetry, Grafana et Clickhouse, offrant une vue complète sur les performances et l’état de santé de chaque service déployé. Cette capacité de surveillance est essentielle pour identifier rapidement les problèmes et optimiser les performances.
La gestion des secrets est gérée par l’implémentation de Hashicorp Vault, offrant une approche centralisée et sécurisée qui améliore la sécurité des services et simplifie les processus opérationnels.
La plateforme permet également de créer des environnements isolés avec Vcluster, bénéfique pour les développeurs des différents clubs. Ils peuvent tester et développer dans des environnements séparés sans impacter l’infrastructure principale. Cette fonctionnalité favorise une approche de développement anticipatif, où les tests et la détection des erreurs se font plus tôt dans le cycle de développement.
La gestion du HTTPS et de l’ingress est assurée par Cert-Manager et Contour, fournissant une configuration sécurisée pour l’accès aux services. Cette combinaison assure l’accessibilité et la sécurité des services déployés, avec une gestion automatisée des certificats SSL/TLS. Les phases suivantes de notre travail et dans nos futures initiatives.
Apprentissages et Compétences Acquises
Thomas
Dans le projet Plateforme Cedille, j’ai pris en charge la configuration d’OpenTelemetry, incluant le collecteur et l’opérateur, enrichissant ainsi ma compréhension de l’observabilité des systèmes. En parallèle, j’ai utilisé mes compétences en Golang pour intégrer des traces dans l’application calidum-rotae, en appliquant les principes du tracing distribué pour optimiser le monitoring et le débogage. J’ai également appris à utiliser Clickhouse pour le stockage et l’analyse des données collectées d’OpenTelemetry, et Grafana pour leur visualisation. Cette combinaison d’OpenTelemetry, Clickhouse et Grafana a créé un écosystème de monitoring complet, me permettant de voir comment ces technologies interagissent et se complètent.
Jonathan
Rejoindre ce projet a été pour moi une première expérience dans la création d’une infrastructure informatique. Apprendre à configurer et utiliser les différents services a été un des points forts pour moi. J’ai pu voir comment chaque service apporte sa pierre à l’édifice et comment tout s’imbrique pour créer un système fonctionnel. Cette compréhension pratique m’a armé d’une solide base pour estimer l’effort requis pour déployer chaque service et dimensionner les ressources nécessaires, que ce soit pour une migration d’envergure ou la mise en place d’une nouvelle infrastructure.
Ce projet m’a offert un modèle de référence, non seulement pour mes futurs projets, mais aussi pour quiconque s’intéresse à notre travail, étant donné que tout le projet est accessible publiquement. C’est une expérience qui me sera utile bien au-delà du cadre de ce projet.
Au-delà des aspects techniques, ce projet m’a permis de voir concrètement comment la division du travail en itérations et la planification en fonction des retours ont été des aspects clés qui ont permis une adaptabilité et réactivité productive et continue à travers les itérations.
Michael
Avec ce projet, j’ai eu l’opportunité d’apprendre comment utiliser et concevoir une bonne structure de projet avec Kustomize. Également, j’ai appris comment utiliser ArgoCD pour déployer des applications selon l’approche GitOps. J’ai aussi collaboré avec mes coéquipiers sur les autres aspects du projet, ce qui a été une bonne occasion de pratiquer mes habiletés en communication et en travail d’équipe. Ce qui est de plus grande valeur pour ce projet est le fait qu’on a bâti un tout nouveau système, en équipe. Ainsi, on a débuté avec une idée initiale, discutée, analysée, décidée, architecturée et implémenté chaque niveau du système, ce qui est une expérience de valeur incalculable.
Simon
Avant de démarrer ce projet, j’avais déjà une expérience superficielle avec plusieurs de ces outils. Toutefois, c’était la première fois que j’avais l’occasion d’explorer plus en profondeur ces technologies qui, je crois, formeront le futur des opérations à grande échelle d’entreprises. Notamment ce qui concerne la gestion des secrets et du stockage, je crois que nous avons configuré les outils de façon très intéressante et que cela fonctionnerait très bien pour de milliers de serveurs.
Mais surtout, j’ai beaucoup appris en ce qui concerne le travail d’équipe et l’organisation du travail. Ce projet comportait peu d’objectifs fixes et il aura fallu mettre en place certaines mesures pour atteindre la rigueur requise pour avancer le projet à rythme satisfaisant. Mettre en place de fort processus de suivi des tâches, de Pull Requests, d’ateliers de travail réguliers et plus fut essentiel à la réussite de ce projet.
Conclusion
En rétrospective, le projet Plateforme CEDILLE a été une expérience formatrice, riche en enseignements techniques et en gestion de projet. Nous avons relevé le défi de concevoir et de mettre en place une infrastructure informatique complexe, ce qui a demandé une coordination minutieuse et une collaboration étroite entre les membres de l’équipe.
Une des leçons clés tirées de ce projet est la nécessité de mieux prioriser notre carnet de travail. Avec le recul, nous avons réalisé que certaines opérations étaient bloquantes et auraient dû être traitées en priorité. Par exemple, la configuration de Vault, un composant clé pour la gestion des secrets, aurait pu être réalisée plus tôt étant donné que plusieurs autres services dépendaient de sa mise en place. Cette prise de conscience sera cruciale pour l’efficacité de nos futurs projets.
Avec l’infrastructure principalement en place, notre prochaine étape est de planifier et de réaliser la migration des services existants. Cette phase requiert une gestion méticuleuse pour assurer une transition sans heurts, en mettant l’accent sur la minimisation des interruptions de service et l’optimisation de la performance et de la sécurité.
Pour les futurs projets, notre conseil serait de valoriser l’adaptabilité et la capacité à répondre aux changements imprévus. La flexibilité dans la planification et la volonté de réviser les stratégies face à de nouvelles informations ont été des facteurs clés dans le succès du projet.
En somme, ce projet a été une expérience enrichissante qui a dépassé nos attentes en termes d’apprentissage et de développement professionnel. Nous sommes enthousiastes à l’idée d’appliquer ces compétences et ces connaissances acquises dans les phases suivantes de notre travail et dans nos futures initiatives.
Annexes
Document de vision: https://wiki-cedille-etsmtl-ca-git-vision-cedille.vercel.app/docs/overview/ Sprints: https://wiki-cedille-etsmtl-ca-git-vision-cedille.vercel.app/docs/sprints/ Répertoire Git: https://github.com/ClubCedille/Plateforme-Cedille Suivi des tâches : https://github.com/orgs/ClubCedille/projects/3
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.